离线推荐
集体智慧
集体智慧是指在大量人群的行为和数据中收集答案,帮助对整个人群得到统计意义上的结论
这些结论是在单个个体上无法得到的,它往往是某种趋势或者人群中共性的部分。
协同过滤
协同过滤 Collaborative Filtering, CF
- 协同过滤利用集体智慧,把喜好相似的用户所喜欢的物品进行相互推荐
- 协同过滤一般是在大量的用户中发掘出一小部分和你喜好比较类似的,这些用户成为一个集合,然后根据他们喜欢的其他东西组织成列表推荐给你
- 协同过滤相对于集体智慧而言,它从一定程度上保留了个体的特征,所以它更多可以作为个性化推荐的算法思想
协同过滤的实现
要实现协同过滤,需要以下步骤:
- 收集用户喜好
- 找到相似用户和相似物品
- 计算推荐
如何收集用户喜好?
本推荐系统从简单起见,仅通过对商品的评分判断用户喜好,不涉及权重、负分等
如何找到相似用户和相似物品?
对用户评分行为进行分析,得到用户喜好后,可以基于相似用户或者基于相似物品进行推荐
目前主流的协同过滤算法有两种:
- 基于用户的 CF
- 基于物品的 CF
这两种方法都有一个核心问题:需要计算相似度
本推荐系统采用基于向量 Vector 的余弦相似度进行计算
余弦相似度
以二维空间为例,根据数学公式:

移项,可以得到两向量之间的夹角余弦值
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小
余弦值越接近1,就表明夹角越接近 0 度,也就是两个向量越相似,这就叫”余弦相似度”
在 用户-物品
User-Item的二维矩阵中
- 将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度
- 将所有用户对一个物品的偏好作为一个向量来计算物品之间的相似度
点乘(内积,数量积)
在空间中有两个向量
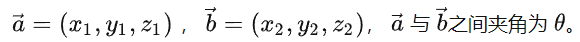
从代数角度看,点乘是
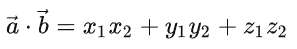
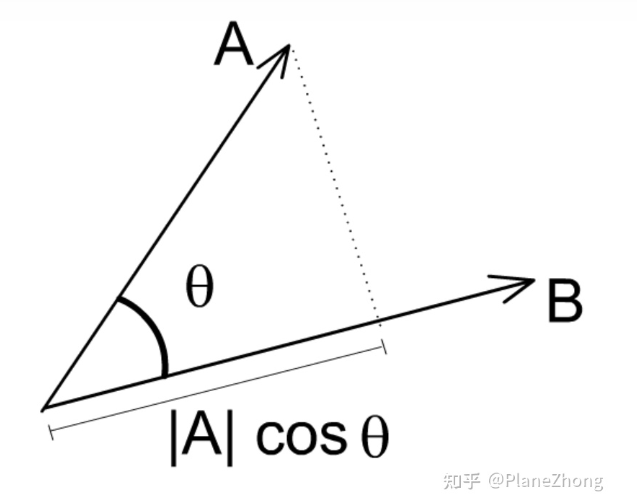
从几何角度看,点乘是
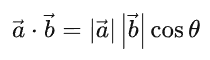
即两向量长度和其夹角余弦值之积
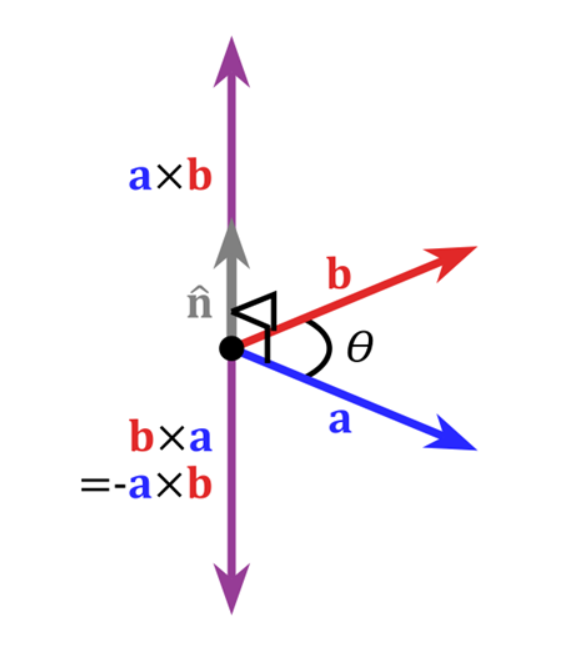
叉乘(外积,向量积)
点乘的结果是一个值(标量)
而叉乘的结果是一个向量
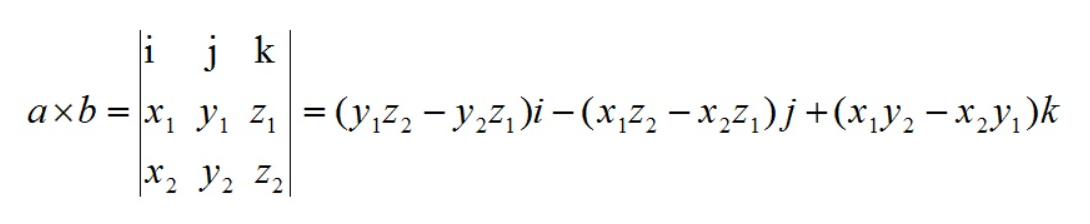
余弦相似度的实现
本系统利用 jblas 框架的 DoubleMatrix 类计算余弦相似度
通过 ALS 算法训练出的模型,不仅可以拿到预测集(用于离线推荐),还可以拿到各个商品的特征值 productFeatures
由 <productId, features> 二元组,可以构造对应商品的特征向量 (productId, new DoubleMatrix(features))
计算出所有商品之间的余弦相似度后,将结果写回数据库(一对多,一个商品对应多个相似商品),可作为实时推荐的数据集
def consinSim(product1: DoubleMatrix, product2: DoubleMatrix): Double = {
product1.dot(product2) / (product1.norm2() * product2.norm2())
}public double norm2() {
double norm = 0.0;
for(int i = 0; i < this.length; ++i) {
norm += this.get(i) * this.get(i);
}
return Math.sqrt(norm);
}xxx.dot(yyy) 即点乘
xxx.norm2() 表示欧几里得范数,也表示向量模
L1 范数
向量中各元素的绝对值之和
L2 范数(欧几里得范数,向量模)
向量中各元素的平方相加,然后开根号
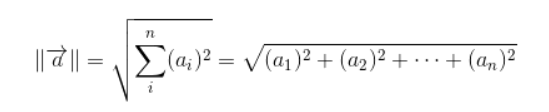
如何计算推荐?
经过前面的计算可以得到相似用户、相似物品
基于用户的 CF (User CF)
将相似用户喜欢的物品推荐给当前用户
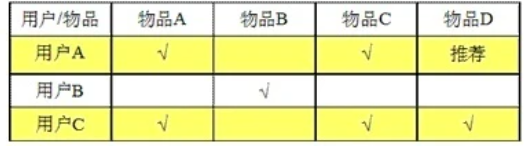
基于物品的 CF (Item CF)
基于用户对物品的偏好,推荐相似物品给他
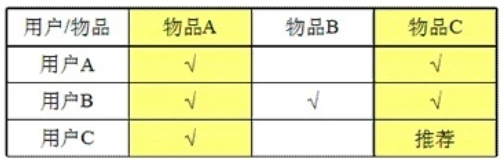
对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的都喜欢物品 C,得出物品 A 和物品 C 比较相似,
而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C
两者对比
User CF 和 Item CF 都是基于协同过滤推荐的两个最基本的算法,两者并无好坏之分,具体要看应用场景
- 对于 User CF,由于用户一般喜欢热门商品,所以更可能推荐热门商品,这可能导致推荐商品的精度不足
- 对于 Item CF,推荐的商品可能会局限在某一领域内,这可能导致推荐商品的多样性不足
从上面的分析,可以得出:
这两种推荐都有其合理性,但都不是最好的选择
实际上,对于推荐系统的最好选择是 User CF 和 Item CF 两者相结合,这就是 ALS 算法的思想
ALS 算法
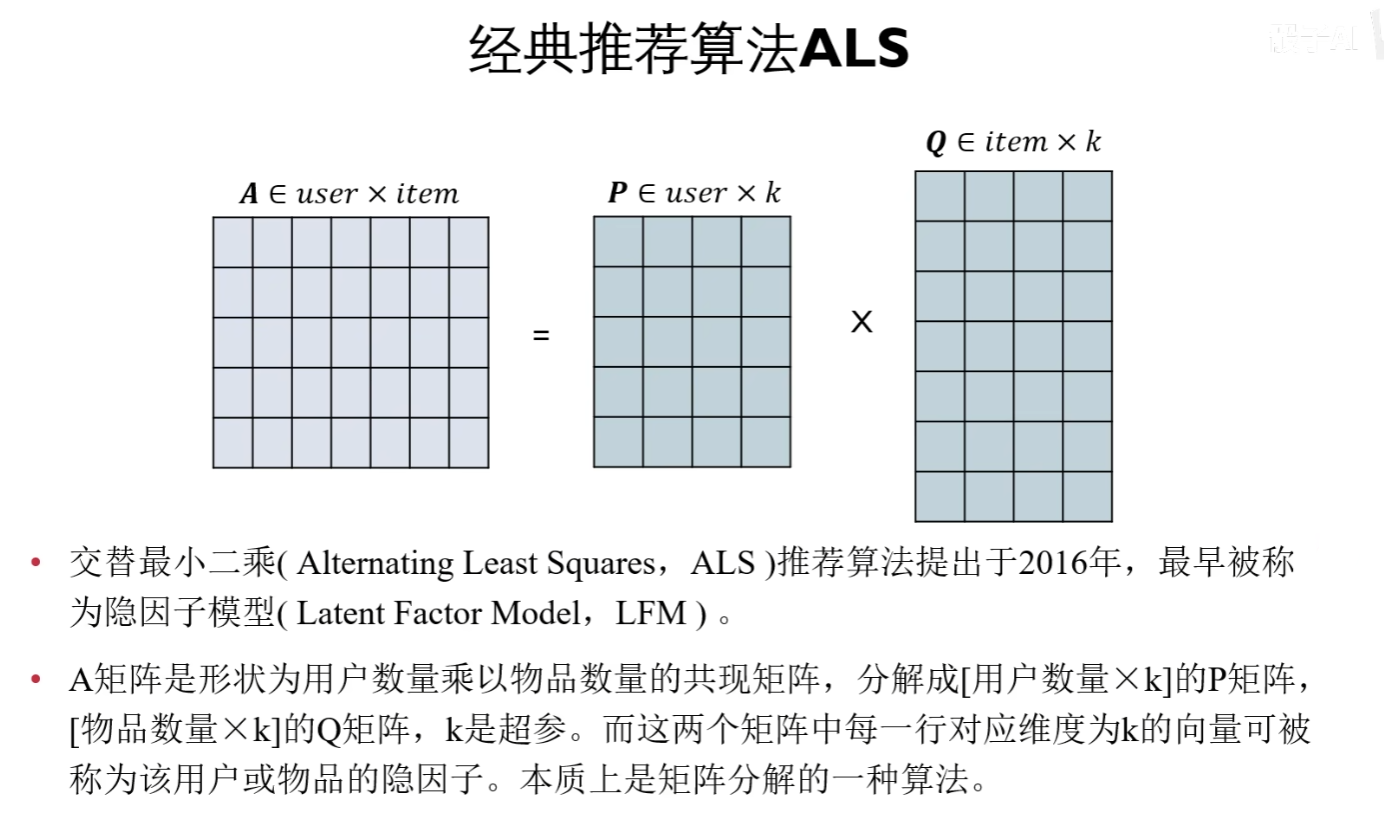
ALS 通过观察到的所有用户对物品的评分,来推断每个用户的喜好并向用户推荐适合的物品,但是 ALS 无法准确评估新注册的用户,这也称为冷启动问题
ALS 是基于矩阵分解的一种方法
矩阵分解
以商品推荐为例,推荐所使用的数据可抽象为一个 m*n 的矩阵 R,每行代表一个用户对所有商品的评分,每列代表所有用户对一个商品的评分
其中 R 是一个稀疏矩阵,因为一个用户只浏览过所有商品中的一小部分且对其评分,通过矩阵分解,可以将该矩阵分解成两个小矩阵的点乘 R = P·Q
矩阵R,用户对商品的评分

矩阵P,用户对特征的评分(也可以理解为对某一类商品的评分),其中 F 是隐藏特征
如一本关于计算机的书,特征可以是 计算机、书

矩阵Q,商品特征所占的比值,如一本关于计算机的书,计算机 0.9,教材 0.9,小说 0.1
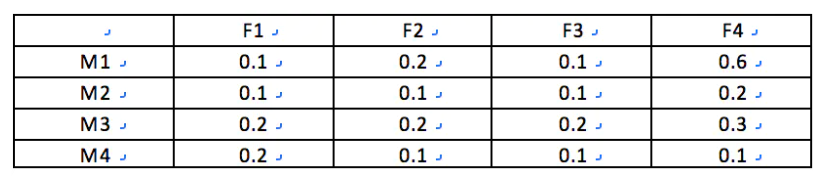
分解之后的矩阵,变成了根据特征数决定向量的维度
为什么进行矩阵分解呢?
因为推荐使用的矩阵不仅是稀疏的,而且往往是低秩的,矩阵分解相当于进行了特征提取或者矩阵的降维
实现过程
ALS 算法是一种协同过滤算法,从协同过滤的分类来说,ALS 属于 User-Item CF,也叫作混合 CF,它同时考虑了 User 和 Item 两个方面
用户、商品的关系,可以抽象为一个三元组 <User,Item,Rating>
Spark 实现
ALS 在 Spark MLlib 中已经有实现,需要先训练出一个模型,再通过模型进行预测
训练数据需要使用 ALS.train(),传入训练集
预测数据需要使用 model.predict(),输出预测集,再通过测试集测试准确度
ALS.train() 的参数
在 ALS.train 方法中涉及三个控制参数,他们的选取影响着预测的精度
// 定义模型训练的参数,rank隐特征个数,iterations迭代次数,lambda正则化系数
val (rank, iterations, lambda) = (5, 10, 0.1)
// rank:表示隐特征的维度 K,要使用多少个特征
// iterations:迭代次数,交替相乘的次数
// lambda:正则化参数
val model = ALS.train(trainData, rank, iterations, lambda)rank:矩阵分解时对应低维矩阵的维度,即特征个数
如果该值太小会导致欠拟合,即拟合得不够,误差很大,训练集和测试集表现都不好
如果该值太大会导致过拟合,即拟合能力太强,只局限于训练集的特征,泛化能力差,在训练集表现好,在测试集表现差
一般取 5 - 100
iterations:矩阵分解后,用交替二乘法求解时迭代的最大次数
该值越大,结果越精确,也越耗时
一般取 10 - 20
lambda:正则化系数
若设置很大,可以防止过拟合问题
若设置很小,其实可以理解为直接设置为0,那么就不会有防止过拟合的功能了
一般可以从 0.0001、0.001、0.01、0.1、1、10 每次十倍逐次尝试,找到合适的值之后再缩小范围
RMSE 均方根误差
关于
rank、iterations、lambda的取值,是编写本系统的一个主要的问题这里是另外编写了一个类
ALS_Trainer来模拟离线推荐的过程,并在代码执行过程中,通过for循环,不断调整三个参数的取值,找到均方根误差最小的一组,作为最终离线推荐模块ALS.train()方法的参数值
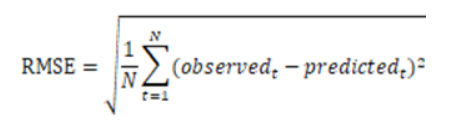
RMSE (Root Mean Squared Error) 与标准差对比:
标准差是用来衡量一组数自身的离散程度
均方根误差 RMSE 是用来衡量观测值与真值之间的偏差,它们的研究对象和研究目的不同,但是计算过程类似
方差
标准差,即方差的算术平方根
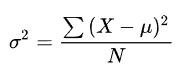
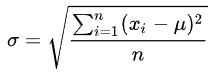
TF - IDF
TF - IDF 是一种用于信息检索和文本挖掘的常用加权技术,常用于挖掘文档中的关键字或关键词
TF - IDF 即 Term Frequency–Inverse Document Frequency,词频 - 逆向文档频率
TF 词频

IDF 逆向文档频率
此时需要一个语料库(corpus),用来模拟实际语言环境
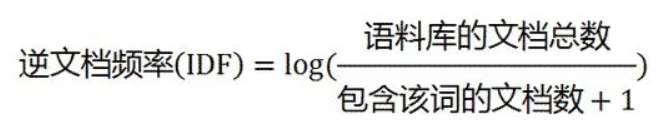
如果一个词越常见,log 值越接近 0,即逆向文档频率越接近 0
计算 TF - IDF
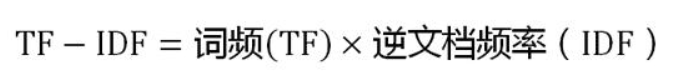
由上式可知,TF - IDF 的值与一个词在某个文档的出现次数成正比,与该词在所有文档的出现次数成反比
也就是说,TF - IDF 值越高,越能代表该词在这个文档的重要性,由此得到这个文档的关键词
TF - IDF 的实现
Spark 已经有关于 TF - IDF 的实现,使用很方便,只需要调用对应的类和方法即可
// 1 分词
val tokenizer = new Tokenizer().setInputCol("tags").setOutputCol("words")
val wordsDataDF = tokenizer.transform(productTagsDF)
// 2 计算 TF
val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(800)
val featurizedDataDF = hashingTF.transform(wordsDataDF)
// 3 计算 IDF,同样可以得到一个 Model 模型,与推荐模块类似
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedDataDF)
// 4 计算 TF-IDF
val rescaledDataDF = idfModel.transform(featurizedDataDF)基于内容的推荐
本系统中的商品详情包含 tags 标签信息,用于说明该商品的特性
因此,可以对 tags 的内容进行提取,得到其特征向量,再利用离线推荐的方法,得到基于内容的推荐(UGC)
实时推荐
离线推荐是综合所有历史评分数据进行计算的,而实时推荐需要根据用户最近的评分数据进行计算
实时推荐最大的要求是响应迅速,为了达到这个目标,可以在已有的数据集(如之前通过余弦相似度得出的相似商品)的基础上再进行少量计算
总之,无论离线推荐还是实时推荐,都是基于 ALS 算法的预测结果集来实现的
MongoDB 与 MySQL
非关系型数据库
NoSQL,表示 Not Only SQL,非关系型的分布式数据库,不提供 ACID 特性
键值数据库(Key - Value)
Redis
文档数据库(JSON)
MongoDB
分布式数据库
优点
- 数据形式灵活,可以是键值对形式(Key - Value)、文档形式(JSON)
- 对于大数据量处理速度快、效率高
缺点
- 不提供 SQL 支持
- 不提供 ACID 特性,不保证数据的安全性、一致性等
- 功能没有关系型数据库齐全
关系型数据库
采用关系模型来存储数据的数据库,简单来说,关系模型就是二维表格模型
优点
- 容易理解,二维表结构贴近真实世界
- 使用方便,SQL 语句在不同关系型数据库通用
- 提供事务的 ACID 特性,有效解决数据不一致问题
ACID 特性
A:Atomicity,原子性
整个事务,要么全部完成,要么全不完成,不允许停留在中间状态
比如,若事务执行过程中发生错误,则需要回滚到事务执行前,就像事务没有执行过一样
C:Consistency,一致性
事务开始前和结束后,数据库的完整性不会被破坏
比如,A 给 B 转账,不论转账操作是否成功,两者总金额不变
I:Isolation,独立性
两个事务执行时相互独立,互不干扰
并发环境下,两个事务修改相同数据时,其中一个事务所看到的数据,要么是另一个事务修改前的情况,要么是另一个事务修改后的情况,事务不可能查看到中间状态的数据
这里涉及到隔离性的事务隔离级别
D:Durability,持久性
最容易理解的特性,事务执行完成后,对数据库的修改是永久性的,即数据永久保存在数据库中,不会被回滚
事务隔离级别
读未提交(Read-Uncommitted)
事务可以读取到其他事务尚未提交的数据
读已提交(Read-Committed)
事务可以读取到其他事务已提交的数据
比如,在事务执行过程中,其他事务修改了同一数据,那么可能导致该事务前后两次查看的数据不同
可重复读(Repeatable-Read)
事务执行过程中,两次查看同一数据的结果一定是相同的,即能确保同一事务多次查询的结果一致
可串行化(Serializable)
最高、最严格的事务隔离等级,每个事务必须一个一个执行,完全杜绝了事务之间的干扰
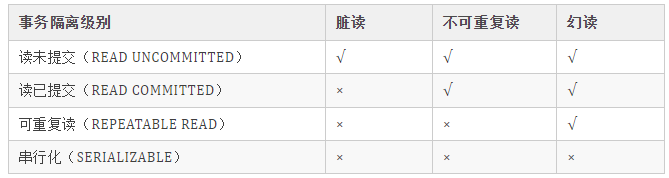
并发数据问题
脏读(读取脏数据)
事务可以读取到其他事务中未提交的数据,而未提交的数据可能会发生回滚,这种数据称之为脏数据
不可重复读(前后多次读取,数据内容不一致)
一个事务可以读取到其他事务提交的结果,所以该事务前后两个时间段的查询中,可能会得到不同的结果
幻读(前后多次读取,数据总量不一致)
一个事务执行时,另一事务插入了一些数据,该事务前后两次查询时,发现数据总量不一致,不知道为什么多出一些数据,就像发生幻觉一样
缺点
- 大数据量读写效率低,受限于硬盘 IO
- 高并发读写效率低,传统关系型数据库的最大连接数有限
- 不够灵活,需要遵守关系模型,需要事先知道数据类型
虚拟机启动
关闭防火墙
systemctl stop firewalld
启动 redis
/usr/local
./redis-server
ps -ef|grep redis 查看是否启动成功
启动 zookeeper 和 kafka
/opt
bin/zookeeper-server-start.sh -daemon config/zookeeper.propertiesbin/kafka-server-start.sh config/server.propertiesWindows 启动
启动 redis
C:\Users\77597\Desktop\Redis
cmd输入
redis-server.exe redis.windows.conf启动 zookeeper 和 kafka
C:\Users\77597\Desktop\kafka\kafka\kafka_2.11-0.10.2.1\bin\windows
zookeeper-server-start.bat ..\..\config\zookeeper.propertieskafka-server-start.bat ..\..\config\server.properties- Post link: http://example.com/2023/02/18/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.